最近又遇到一个问题,来水一篇博客。
事情是这样的,我统计了一些信息,得到一个A表;上级发下来另一个B表,要核对两个表的信息是否一致。
然而麻烦的事情在于两个表的格式并不一样,A表示意如下(里面的信息被我改了):

B表示意如下:
如果用过tidyverse的话,自然地就想到了tidyr的格式转换。事实上使用tidyr和stringr的结合很容易就可以解决这个问题。
Tidyverse是R语言中一系列用来做数据分析处理的包,可以极大地提升与优化数据分析处理。例如先进的作图工具
ggplot2;用于数据聚类分析的dplyr;用于数据格式转换的tidyr;用于字符串处理的stringr等。
1. 解决问题
解决这个问题很简单,思路如下:把原来的A表拉长,把编号排成一列;修改B表的数字格式,二者比较即可。
做法如下,我已经使用readxl(也是tidyverse中的一个包,可以方便地读取excel格式)读取了文件,表A这里命名为dt_old,表B这里命名为dt_new:
|
|
得到的表如下:
# A tibble: 260 x 6
单位 学号 姓名 笔记本数量 Num value
<chr> <dbl> <chr> <dbl> <chr> <dbl>
2 单位1 82 张三 8 编号2 13557
1 单位1 82 张三 8 编号1 19257
3 单位1 82 张三 8 编号3 19923
4 单位1 82 张三 8 编号4 8725
5 单位1 82 张三 8 编号5 9878
6 单位1 82 张三 8 编号6 9425
7 单位1 82 张三 8 编号7 18871
8 单位1 82 张三 8 编号8 19394
9 单位1 82 张三 8 编号9 NA
10 单位1 82 张三 8 编号10 NA
# ... with 250 more rows
这里可以注意到,一些人是没有后面的编号的,所以其值为NA。
把A表的编号提取出来,命名为old:
|
|
old数据如下:
r$> old
[1] 3364 3365 3366 8715 8716 8717 8718 8719 8721
[10] 8722 8723 8724 8725 8726 8727 8728 8729 8730
[19] 8731 8822 8823 8849 8850 8885 8886 8898 8901
[28] 8902 8903 8904 8905 8906 8907 8908 8921 9276
..............
其中B表的数据格式为0544-0XXXXX,可以看出前面的部分都是无用的,所以删掉即可,这里把处理的结果命名为new:
|
|
接下来就好比较了,首先看一下个数:
|
|
发现个数居然就不一样,仔细一想,是因为我保存old表的时候,还有一位同学有一项没有填写,数字为13551,所以给old修补一下:
|
|
接下来就比较好办了,因为这个需要逐项比较,可以生成一个data frame:
|
|
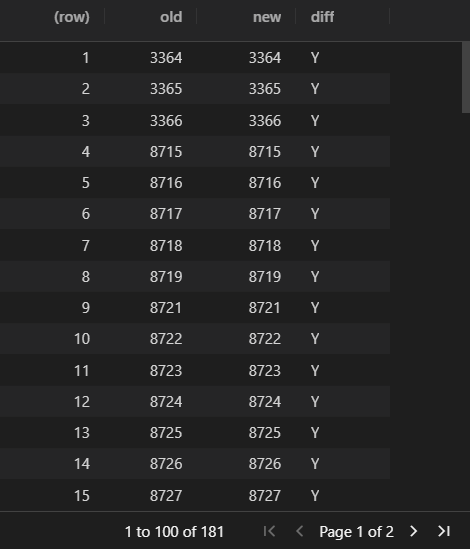
算一下有多少N:
|
|
结果为0,说明两个表的值是一样的。
2. 问题思考
这个问题可以有很多延伸:
2.1. 算法问题
从算法的角度来看,这个比较效率比较低,即排序后一个个来比较,每一个表排序的复杂度都是$O(nlgn)$,而二者比较复杂度为$O(n)。但是胜在数据量不大,而且排序比较R语言容易实现一些。
因为这些值都是不同的,所以更好的思路是使用数据结构set,把A表建立为set,然后对B表中的每一个元素都去找是否在set中,复杂度为O(n)。
set是这样一种数据结构,set中每个元素都是唯一的,并且可以在$O(1)$的时间内发现某个元素是否在set内。
进一步的,如果存在相同值呢?答案是可以同样利用set,只需要建立set后多判断一下数字个数是否发生变化即可。然后对于B表中每个元素判断是否在set中即可。
还可以有其他的思路,欢迎各位大佬补充~
2.2 表格转换问题
表A和表B是在工作中常见的两种表格式,前者称为宽表,后者称为长表。在数据分析中,长表更加好用,因为刚好可以对应为一个data frame结构,因此拿到一个表后一般都需要洗成这种结构。
在这个例子中,还可能发生的场景:
2.2.1 长表补全
在本例子中可以看到,B表填写的时候,为了方便起见,并没有补全,那么要补全的话怎么处理呢?
代码很简单,写个循环即可:
|
|
这里要注意ifelse的用法,他对于第一个逻辑判断的数据格式是会和后面的TRUE或者FALSE的数据格式是一致的,所以这里不能只判断1个值,需要同时判断4个值。
2.2.2 字符串处理
如果想要把A表中的编号改成为B表中编号格式,那么这样处理:
|
|
结果如下:
|
|
这个处理是用stringr完成的,可以看出其强大。
3. 总结
R语言的光环很大程度上被现在流行的Python所遮蔽,但实际上R语言非常强大且易用,现在生活工作离不开数据,如果能将R语言用好的话可以解决大量的问题。例如前些年特朗普政府中有一位自称为“抵抗者”的高官在纽约时报匿名发文,很快就有人使用R语言分析出这位匿名高官最有可能就是蓬佩奥,其中用到的就是tidyverse和tinytext两个包。
综上所述,一个生活中的小问题也有很多值得琢磨的地方,时间所限,有些其它的想法就不写了。
以上。