1. 引言
本文题图是统计学中著名的例子,lady tasting tea,女士品茶。它讲的是Fisher最初关于统计学假设提出的一个例子。这个故事是这样的:
大约19世纪20年代,在剑桥大学,几位绅士和他们的妻子坐在一起品茶。其中一位夫人坚持认为,把茶倒入奶中,和把奶倒入茶中,得到的口感是不一样的。有些人认为她完全是在胡说八道,因为混合物的化学成分没有任何区别。但其中一位戴着厚厚的眼镜瘦弱的绅士站起来,说让我们来做个实验吧。
这个例子的实现就是一个统计假设检验, 所谓统计假设检验,指的是一个检验的方法, 通过一组样本的数据来对一个统计假设做判断。
2. 统计假设检验
2.1 统计假设(statistical hypothesis)
统计假设(statistical hypothesis),也叫作验证性数据分析(confirmatory data analysis)。它指的是两个或者多个变量的一个关系的叙述。它可以指(1)关于某个特定统计学参数的值的叙述,比如均值,中位数,众数,方差等。或者是(2)一个特定的变量遵循的某个概率分布的叙述
例如:
- 学校所有学生年龄的平均数是23.4岁
- 学校学生中女生的比例是76%
- 学校中学生的身高H,近似为正态分布
对于假设中关系的叙述,总是有两种情况,要么是A与B有R关系,或者是A与B的R关系不成立。
统计假设具有这样的特征:可以通过观测样本中与假设相关的事实来对它们进行测试。测试的结果就是可以得到结论,来说明是否应该相信假设的说法成立。
2.2 统计假设检验
统计假设检验(statistical hypothesis test)则是统计推断的方法,一般来讲,要比较两组统计数据,或者是一组数据和理想化的模型数据进行比较。基于这两组数据集的关系,提出假设,这个假设就是所谓的备选假设(alternative hypothesis),用这个假设和理想化的零假设(null hypothesis),进而提出两组数据集之间的关系。
- 零假设使用\(H_0\)表示
- 备选假设使用\(H_1\)表示
所谓的零假设(Null hypothesis),是说在两组测试结果中,没有相关性。进而,对零假设的拒绝,就可以说明两种结果中存在关系。
比如,在例子:学校所有学生年龄的平均数是23.4岁中,我们的零假设就是学校所有学生年龄的平均数是23.4岁,而备选假设可以有很多,比如:
- 学校所有学生年龄的平均数不是23.4岁
- 学校所有学生年龄的平均数大于23.4岁
- 学校所有学生年龄的平均数是27.4岁
经过我们的统计假设检验,就可以通过备选假设来拒绝,或者无法拒绝零假设(注意,这里不能是接受)。
统计假设检验的模式很简单,就是给定一组统计数据,来建立零假设和备选假设,然后通过计算来判断这些数据是否可以拒绝,还是不能接受零假设。
2.3 拒绝零假设
这里最核心的一点就是,在统计假设检验中,我们只能拒绝零假设,而决不能接受零假设。
这里经常会用现实中的一个例子来做类比:
在法庭上,被告在被证明有罪之前,一直是无辜的。
这里对于他无辜的判断,就是零假设。而起诉方就通过罗列证据(即所得到的样本)来拒绝零假设。
这是因为在统计假设检验中,我们是通过样本来判断结论的,由于样本的局限性,我们永远无法得到总体的数据。因此基于样本的判断,并不一定正确。
在这一个例子中,我们可以通过一些证据来证明被告确实有罪,但如果证据不足,那么就无法证明被告有罪。但并不能证明被告无罪。
统计学(statistics),是一门收集,分析,展示和解释数据的科学。但很多时候,用到的数据往往并不全面,这不仅仅因为条件限制,同时也是出于方便。在使用样本估计总体的时候,总会存在偏差和错误。就比如上一个例子,很可能嫌疑人确实有罪,但也许他足够狡猾,成功实现了不在场的证明。因此由于证据(样本)的限制,如果贸然由此判断嫌疑人无罪(接受零假设),就得到了错误的结论。
关于如何指定零假设和备选假设, 在后面介绍.
2.4 统计假设检验的几个例子
什么样的情况可以用统计假设检验呢?情况很多,所有关于总体的统计假设都可以做检验,这里简单举几个例子:
- 把牛奶倒入茶和把茶倒入牛奶,口味是否有区别(注明的lady testing tea的例子)
- 检测是否男性比女性更容易受到噩梦的干扰
- 验证月圆对行为的影响
- 确定蝙蝠可以通过回声定位昆虫的距离
- 研究医院的毛毯会不会导致更多的感染
- 选择阻止吸烟最好的办法
3. 两类错误
即便使用了零假设和备选假设,在做统计假设检验中,还是会发生两类错误:
- 第一类错误(Type I error): 在零假设正确的时候, 错误地拒绝了零假设.
- 第二类错误(Type II error): 在零假设错误的时候, 没能拒绝零假设.
两类错误的概率都是可以量化的, 而两种错误, 在现实中的接受程度往往也不同. 例如:
假设要测试一种新型的药物, 对测试的N只小白鼠中, K只在注射药物后死去. 那么什么样的K和N可以让我们认为这个药物可以投入对人类的使用呢?
这个例子中, 零假设是药物是安全的, 如果犯了第一类错误, 那么可能结果就是投入了数十亿的研发经费宣布失败。如果犯了第二类错误, 那么可能造成患者用药后的死亡事件. 显然,第二类错误更加严重一些. 在实际中, 大部分的问题也是更加关注第二类错误, 要尽可能避免第二类错误.
对于第一类错误发生的概率, 用\(\alpha\)表示; 第二类错误发生的概率, 用\(\beta\)表示:
- Pr[Type I error] = \(\alpha\)
- Pr[Type II error] = \(\beta\)
3.1 第一类错误的概率
\(\alpha\)值指的是犯第一类错误的概率, 这个值也被称为是显著性水平(significant level). 这个值是在样本收集前指定的, 根据不同的问题可以指定不同的\(\alpha\)值。 最常用的\(\alpha=0.05\). 因为\(\alpha\)表示在零假设为真的情况下拒绝零假设的概率, 而当零假设为真的时候, 只有样本值显著与零假设有差异, 才会拒绝零假设, 也就是说, \(\alpha\)表示了在概率分布中最靠外的地方. 因此就有以下三种情况:
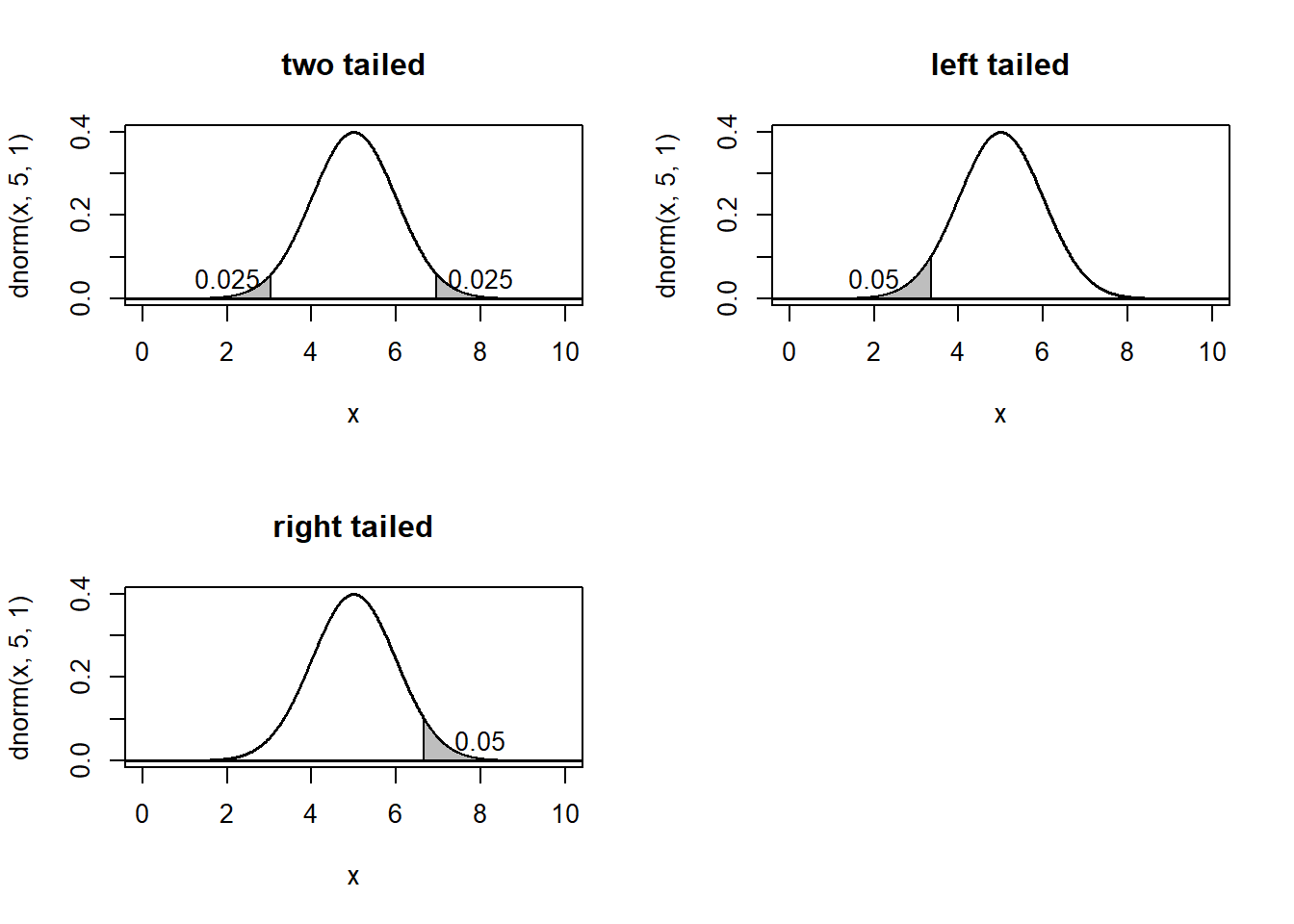
对于图中灰色的部分, 称为临界域(critical region, 也叫\(\alpha\;region\)), 如果样本的值落入了这一区域, 那么就称这一结果统计显著(statistical significant). 注意统计显著并不一定等价于实际显著. 例如, 在统计学上可以发现, 男性和女性的IQ并不相同, 但统计学的结果是否足以证明有实际的应用呢?
由于统计学显著的大量使用, 对于它的争议也逐渐产生, 特别是对于统计学显著和实际显著的区别. 参见wikipedia的讨论
3.2 第二类错误的概率
\(\beta\)表示第二类错误发生的概率, 因此\(1-\beta\)就表示不犯第二类错误的概率, 因为一般来讲, 避免第二类错误更加重要一些, 所以1-\(\beta\)的值就受到更多关注, 把它称为检验的势(Power). 即一个检验的势, 指的是在零假设为假并且判断正确的概率. 检验的势越高越好, 强势检验也被称为高效率检验.
势的计算也有对应的公式, 要求势的大小, 需要知道样本大小, 效应值(effect size), 以及显著性水平. 事实上, 以上三者和势, 已知其中任意三个, 就可以求出另一个值。
关于势, 效应值等概念较为复杂, 这里不做过多介绍。
4. p-value
为了量化对零假设的拒绝的程度, 引入了p值(p-value), 指的是在给定的统计学模型下, 当零假设为真的时候, 实际观测数据落入极端值的概率。极端值可以是左极端\(\{X \geq x\}\)(left-tail event) 或者是右极端 \(\{X \leq x\}\)(right-rail event), 也可以是双极端(double tail event). 从\(\alpha\)的介绍中已经明白, 极端值就是落在临界域(critical region)的值. 当样本值落在这里的时候, 可以统计学显著地拒绝零假设.
p值可以这样给出:
- \(Pr(X \geq x|H)\) for right tail event
- \(Pr(X \leq x|H)\) for left tail event
- 2 \(min\{Pr(X \geq x|H), \; Pr(X \leq x|H)\}\) for double tail event
p值越小, 出现在零假设外极端值的概率也就越小。因此在测试中, 这样的样本本应该极不可能出现的, 却被观察到了, 也就说明零假设是可以拒绝的。即p值越小,越能拒绝零假设。
对于p值来讲, 仅仅使用概率来描述还是不够的. 对于一个特定的问题来讲, p究竟为多大才应该拒绝零假设? 对于不同的问题, 往往有着不同的选择。\(\alpha\)值选的越小, 越不容易拒绝零假设。
当\(Pr(p\leq \alpha | H)\)时, 拒绝零假设. 所以有: \[ Pr(Reject \; H) = Pr(p\leq \alpha | H) = \alpha \]
那么问题就来了, 既然有了\(\alpha\)了, 为什么还需要引入P-value呢. 这是因为p值可以更准确地提高显著性水平.
例如, 在\(\alpha = 0.05\)的情况下, 得到的p值为0.02, 很显然, 观测数据落入了临界域, 统计学显著地可以拒绝零假设. 然而注意! 这时候犯第一类错误的概率仍然为5%! 因为指定了\(\alpha\)为0.05! 而如果使用p值作为新的显著性水平, 那么就可以说, 在显著性水平为0.02时, 拒绝零假设. 这样我们就把犯第一类错误的概率降低到了2%. 通过图来直观地说明这个问题:
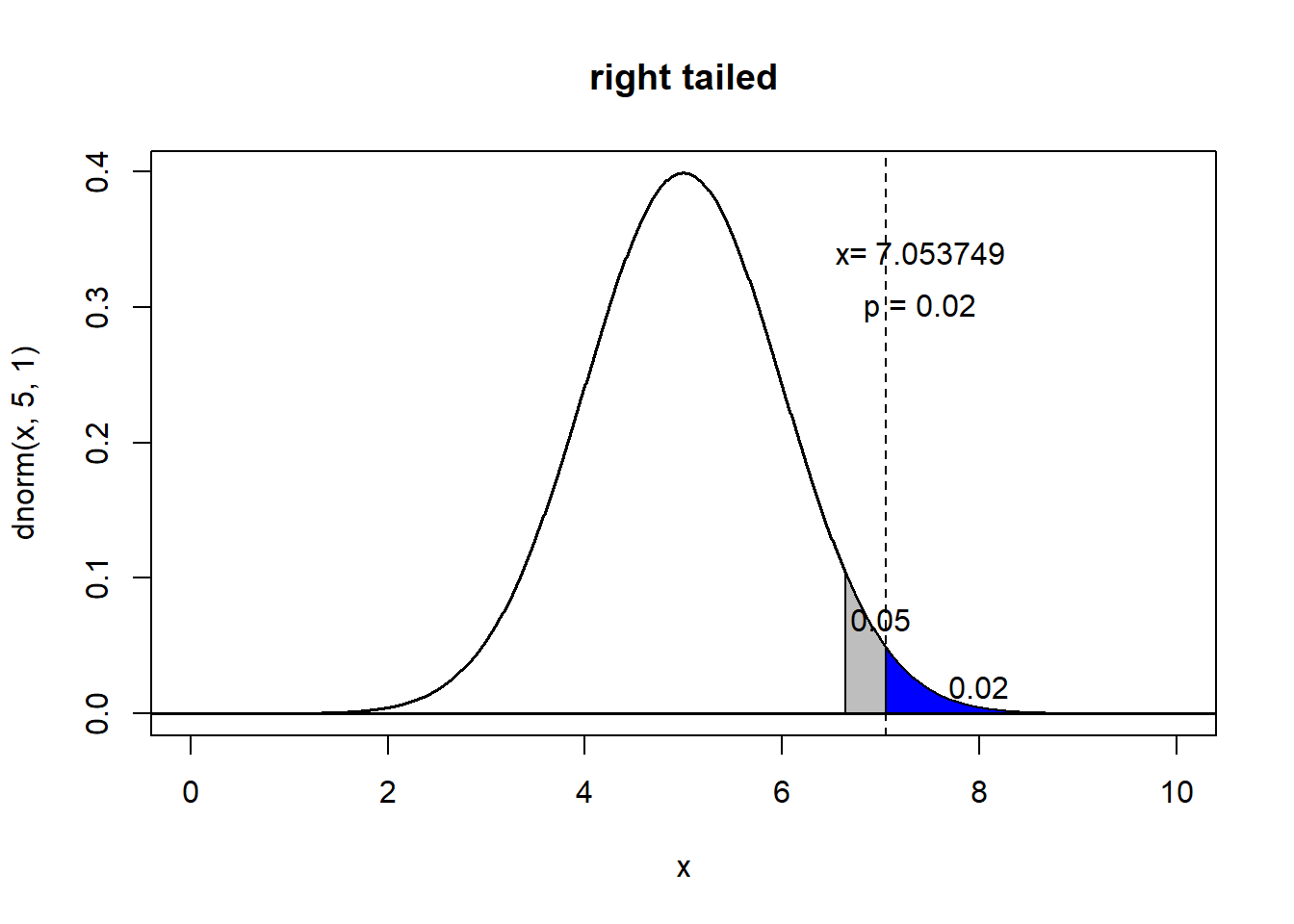
假设数据分布为正态分布,\(H_0: \mu = 5\) , 在做了样本调查后,提出\(H_1: \mu > 5\).
样本中\(\mu = 7.053749\), 使用pnorm求得,此时的概率p为0.02. 落入了\(\alpha\; region\)。这里也可以说,在显著性水平为0.02时,拒绝零假设。
通过p值,相当于在有了\(\alpha\)作为参考的情况下,进一步提高了结果的准确性。因此p值又称为观测的显著性水平(obeserved significant level),在统计学软件上,往往输出p值而不输出\(\alpha\),因为\(\alpha\)是根据不同问题自行决定的。
例如: 在5年前的一次普查中, 发现某学校男生平均身高为165cm. 现在做了一个抽样调查, 认为男生的身高高于165cm. 抽样的5个数据结果为: 172cm, 180cm, 179cm, 160cm, 175cm.
例子是我自己编的, 为了说明方便, 数据量比较小. 这里假设抽样的样本为正态分布, 应该使用t检验(关于什么情况使用什么样的检验,见本文的第二部分),那么直接调用R的t.test结果:
x = c(172,180,179,160,175)
t.test(x, m=165, alternative = "greater")##
## One Sample t-test
##
## data: x
## t = 2.2795, df = 4, p-value = 0.04241
## alternative hypothesis: true mean is greater than 165
## 95 percent confidence interval:
## 165.5313 Inf
## sample estimates:
## mean of x
## 173.2这个问题中,\(H_0:\) 男生平均身高为165cm。 通过结果可以发现,p值为0.04,所以可以说,在显著性水平为0.04的情况下,拒绝零假设。也就是可以拒绝学校男性的身高等于165cm,拒绝错误的概率为0.04。
假如在这一问题中,选择\(\alpha = 0.05\),那么就可以拒绝零假设。而如果令\(\alpha = 0.02\),那么就无法拒绝零假设了。所以可以看出来,使用p-value给问题的讨论带来了更大的自由度和方便。
进一步地,来说明一下这个p值是如何得出的。这个问题中假定了样本为正态分布,并且是单样本的检验(one sample t test,即抽取一个样本,来对一个给定的值做检验)。计算如下:
- \(t = \frac{\bar{x}-\mu}{\frac{s}{\sqrt{n}}}\) 所以代入,求得\(t = ^{(mean(x) - 165) \times \sqrt{5} }/ sd(x)= 2.2795\)
- 按照n-1建立t分布,即
t(4) - 用t值去对应t分布的概率
1-pt(t, 4)=0.04241492, 结果与直接使用t.test结果一致。
5. 统计假设检验的一般流程
- 对于未知的事实,提出一个最初的研究假设。
- 建立
零假设和备选假设,这一步非常关键,错误的零假设会导致结果完全错误。正确指定零假设的关键在于零假设总是会指定一个参数 等于 某个值 - 考虑样本的统计学假设,比如抽样的独立性,比如样本的分布等。样本的数据同样很关键,否则可能得出完全相反的结论。比如错误地拒绝
零假设等。 - 考虑选择检验统计量(test statistic) T, 比如T统计量。不同的检验统计量对应了不同的检验,应用不同的比较上。例如单样本z检验,检验统计量就是z值; 单样本t检验,检验统计量就是t值。
- 推导
零假设下检验统计量的分布,在标准情况下一般是t分布或者正态分布。如上一个例子中,第一步做了t值的计算,第二步就说明样本分布遵循t分布(因为原概率分布为正态分布,而样本大小比较小并且对原分布的标准差未知)。 - 选择显著性水平(significance level, \(\alpha\)),一般都是5%或者1%
- 按照检验统计量(test statistics)的分布来查看对应的检验统计量的值\(t_{obs}\),是否落入拒绝域,拒
绝零假设。
以上是传统的流程,往往通过查表来实现,不需要做额外的复杂计算,但在现在,往往通过值\(t_{obs}\)直接来求对应的p值。讨论p值来给出是否能拒绝零假设。